In Windows WSL, you can access the local disk navigating the path /mnt/c/ for the C: drive, for example.
Sometimes, network drives mounted on boot aren’t automatically mounted within your WSL Linux shell. You can do it manually using the following commands:
# For a drive already mapped in Windows (e.g. Z: drive)
$ sudo mkdir /mnt/z
$ sudo mount -t drvfs Z: /mnt/z
# For a network drive accessible via \\myserver\dir1 in Explorer
$ sudo mkdir /mnt/dir1
$ sudo mount -t drvfs '\\myserver\dir1' /mnt/dir1
How many times I’ve heard “well, a container is like a super light-weight virtual machine“. And yes, true, I admit as well, that I was one of them.
But I wasn’t happy about this answer, so I did some researches and I think now I have a better understanding and I feel the pain of my friends where I was simplistically (and wrongly) saying that – public apologies 😛 🙂
So… let’s start…
Concept 1: Virtual memory.
Virtual memory is the collective memory used by processes (RAM, disk swap, etc).
Of this virtual memory, we have generally a separation beween 2 types:
kernel space: reserverd for the kernel and generally drivers
user space: for the applications, incluse libraries
This separation serves to provide memory protection and hardware protection from malicious or errant software behavior.
NOTE1: User space is not namespace.
NOTE2: FUSE is not really related with this topic, but could confuse someone. So, just to clarify: FUSE – (Filesystem in Userspace) is a software interface for Unix-like computer operating systems that lets non-privileged users create their own file systems without editing kernel code. This is achieved by running file system code in user space while the FUSE module provides only a “bridge” to the actual kernel interfaces.
Modern kernels have cgroupsand namespacecapabilities.
Cgroups can restrict what you can USE -> CPU, memory, storage, network, devices, etc. Also allows to ‘freeze’.
Namespace can restrict what you SEE -> PID, mnt, UID/GID, etc…
Containers runtimes (like LXC, Docker, etc…) are using cgroups and namespaces to create separate isolated user-space entities called ‘containers‘.
Containers have basically no overhead because they are using the same system calls to the host kernel => No need of emuation or virtual machine.
They use the same kernel of the host (this is a key difference with virtualisation). So, currently, you cannot run Windows containers on a Linux host. But you can still run different versions of Linux, as they all share the same kernel.
Virtualisation: fully isolated OS, running its own kernel.
Full virtualised: (eg. VMWare, Virtuabox, ESXi…). The OS in the VM is not aware to be a VM. Hypervisor emulates the hardware platform for the guest OS and then translates the hardware accesses requests to the physical hardware. Hypervisor provides the drivers to the guest OS.
=> higher overhead because hardware virtualisation BUT best isolation and security
Para virtualised: (XEN, KVM) the OS in the VM knows to be virtualised. Drivers are sending instructions directly to the hardware of the host, via the Hypervisor. Hardware is not virtualised BUT the OS runs in isolation.
=> better performance and ability to use recent hardware drivers directly BUT guest OS needs to be modified to use paravirtualised devices
NOTE: Emulation is not platform virtualisation (e.g. QEMU)
With emulation you can emulate different architectures (e.g. ARM/RISC…) on a host that has a differnt instruction set (eg. i386). Performances are cleary not ideal.
As any other Configuration Manager tools, the main goal is automate and keep consistency in the infrastructure:
create files if missing
ignore file/task if already up to date
replace with original version if modified
Typically, Chef is comprised of three parts:
your workstation – where you create your recipes/cookbooks
a Chef server – The guy who host the active version of recipes/cookbooks (central repository) and manage the nodes
nodes – machines managed by Chef server. FYI, any nodes has Chef client installed.
picture source https://learn.chef.io
Generally, you deploy your cookbooks on your workstation and push them onto the Chef Server. The node(s) communicate with the Chef Server via chef-client and pulls and execute the cookbook.
There is no communication between the workstation and the node EXCEPT for the first initial bootstrap task. This is the only time when the workstation connects directly to the node and provides the details required to communicate with the Chef Server (Chef Server’s URL, validation Key). It also installs chef on the node and runs chef-client for the first time. During this time, the nodes gets registered on the Chef Sever and receive a unique client.pem key, that will be used by chef-client to authenticate afterwards.
The information gets stored in a Postgress DB, and there is some indexing happening as well in Apache Solr (Elastic Search in a Chef Server cluster environment).
resource: part of the system in a desiderable state (e.g. package installed, file created…);
recipe: it contains declaration of resources, basically, the things to do;
cookbook: is a collection of recipes, templates, attributes, etc… basically The final collection of all.
Important to remember:
there are default actions. If not specified, the default action applies (e.g. :create for a file),
in the recipe you define WHAT but not HOW. The “how” is managed by Chef itself,
the order is important! For example, make sure to define the install of a package BEFORE setting a state enable. ONLY attributes can be listed without order.
Chef DK: it provides tools (chef, knife, berks…) to manage your servers remotely from your workstation. Download link here.
To communicate with the Chef Server, your workstation needs to have .chef/knife.rb file configured as well:
# See http://docs.chef.io/config_rb_knife.html for more information on knife configuration options
current_dir = File.dirname(__FILE__)
log_level :info
log_location STDOUT
node_name "admin"
client_key "#{current_dir}/admin.pem"
chef_server_url "https://chef-server.test/organizations/myorg123"
cookbook_path ["#{current_dir}/../cookbooks"]
Make sure to also have admin.pem (the RSA key) in the same .chef directory.
To fetch and verify the SSL certificate from the Chef server:
knife ssl fetch
knife ssl check
Chef DK also provides tools to allow you to configure a machine directly, but it is just for testing purposes. Syntax example:
chef-client --local-mode myrecipe.rb
Chef Server: Download here.
To remember, Chef Server needs RSA keys (command line switch –filename) to communicate. We have user’s key, organisation key (chef-validator key).
There are different type of installation. Here you can find more information. And here more detail about the new HA version.
Chef Server can have a web interface, if you also install the Chef Management Console:
Chef Client: (From official docs) The chef-client accesses the Chef server from the node on which it’s installed to get configuration data, performs searches of historical chef-client run data, and then pulls down the necessary configuration data. After the chef-client run is finished, the chef-client uploads updated run data to the Chef server.
Handy commands:
# Create a cookbook (structure) called chef_test01, into cookbooks dir
chef generate cookbook cookbooks/chef_test01
# Create a template for file "index.html"
# this will generate a file "index.html.erb" under "cookbooks/templates" folder
chef generate template cookbooks/chef_test01 index.html
# Run a specific recipe web.rb of a cookbook, locally
# --runlist + --local-mode
chef-client --local-mode --runlist 'recipe[chef_test01::web]'
# Upload cookbook to Chef server
knife cookbook upload chef_test01
# Verify uploaded cookbooks (and versions)
knife cookbook list
# Bootstrap a node (to do ONCE)
# knife bootstrap ADDRESS --ssh-user USER --sudo --identity-file IDENTITY_FILE --node-name NODE_NAME
# Opt: --run-list 'recipe[RECIPE_NAME]'
knife bootstrap 10.0.3.1 --ssh-port 22 --ssh-user user1 --sudo --identity-file /home/me/keys/user1_private_key --node-name node1
# Verify that the node has been added
knife node list
knife node show node1
# Run cookbook on one node
# (--attribute ipaddress is used if the node has no resolvable FQDN)
knife ssh 'name:node1' 'sudo chef-client' --ssh-user user1 --identity-file /home/me/keys/user1_private_key --attribute ipaddress
# Delete the data about your node from the Chef server
knife node delete node1
knife client delete node1
# Delete Cookbook on Chef Server (select which version)
# use --all --yes if you want remove everything
knife cookbook delete chef_test01
# Delete a role
knife role delete web
Practical examples:
Create file/directory
directory '/my/path'
file '/my/path/myfile' do
content 'Content to insert in myfile'
owner 'user1'
group 'user1'
mode '0644'
end
Package management
package 'httpd'
service 'httpd' do
action [:enable, :start]
end
Use of template
template '/var/www/html/index.html' do
source 'index.html.erb'
end
Use variables in the template
<html>
<body>
<h1>hello from <%= node['fqdn'] %></h1>
</body>
</html>
General notes
Chef Supermarket
link here – Community cookbook repository.
Best way to get a cookbook from Chef Supermarket is using Berkshelf command (berks) as it resolves all the dependencies. knive supermarket does NOT resolve dependencies.
This will download the cookbooks and dependencies in ~/.berkshelf/cookbooks
Then to upload ALL to Chef Server, best way:
# Production
berks upload
# Just to test (ignore SSL check)
berks upload --no-ssl-verify
Roles
Define a function of a node.
Stored as objects on the Chef server. knife role create OR (better) knife role from file <role/myrole.json>. Using JSON is recommended as it can be version controlled.
# Push a role
knife role from file roles/web.json
knife role from file roles/db.json
# Check what's available
knife role list
# View the role pushed
knife role show web
# Assign a role to a specific node
knife node run_list set node1 "role[web]"
knife node run_list set node2 "role[db]"
# Verify
knife node show node1
knife node show node2
To apply the changes you need to run chef-client on the node.
Test Kitchen helps speed up the development process by applying your infrastructure code on test environments from your workstation, before you apply your work in production.
Test Kitchen runs your infrastructure code in an isolated environment that resembles your production environment. With Test Kitchen, you continue to write your Chef code from your workstation, but instead of uploading your code to the Chef server and applying it to a node, Test Kitchen applies your code to a temporary environment, such as a virtual machine on your workstation or a cloud or container instance.
When you use the chef generate cookbook command to create a cookbook, Chef creates a file named .kitchen.yml in the root directory of your cookbook. .kitchen.ymldefines what’s needed to run Test Kitchen, including which virtualisation provider to use, how to run Chef, and what platforms to run your code on.
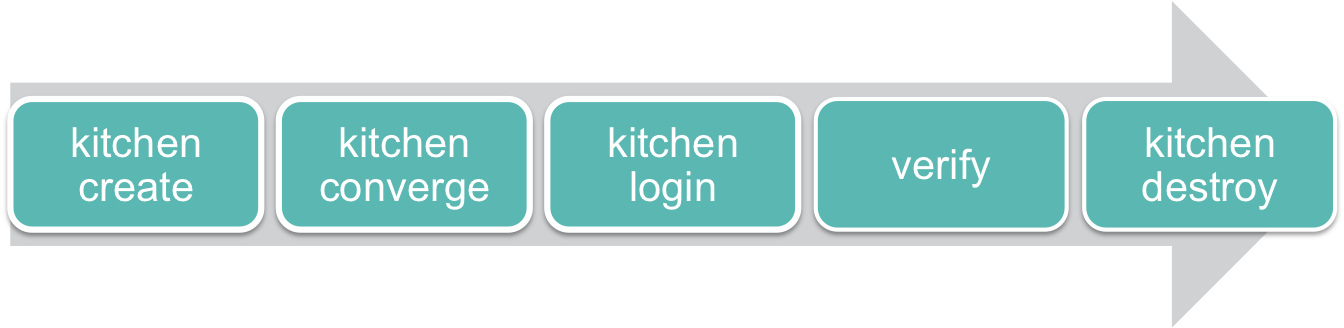
Kitchen steps:
Kitchen WORKFLOW
Handy commands:
$ kitchen list
$ kitchen create
$ kitchen converge
In the Cloud era, virtual servers come with no swap. And it’s perfectly fine, cause swapping isn’t good in terms of performace, and Cloud technology is designed for horizontal scaling, so, if you need more memory, add another server.
However, it could be handy sometimes to have a some more room for testing (and save some money).
So here below one quick script to automatically create a 4GB swap file, activate and also tune some system parameters to limit the use of the swap only when really necessary:
NOTES: Swappiness: setting to zero means that the swap won’t be used unless absolutely necessary (you run out of memory), while a swappiness setting of 100 means that programs will be swapped to disk almost instantly.
This is an example for a shared called “Downloads”.
This share will be mounted under /home/user/Downloads forcing uid/gid to 1000, which it will be the one related to the myuser
NOTE: To have VMWare Workstation able to run MacOS X, you need to patch your version using this . If the file is no longer available, you can get a copy here.
If you want to force specific hardware parameters (like serial number etc), you need to add the following in your vmx file:
Puppet is a quite powerful configuration manager tool which allows you to configure automatically hosts and keep configurations consistence.
I did some tests using 3 VMs:
puppetmaster (server)
puppetagent01 (client)
puppetagent02 (client)
Of course, most of the work is done on puppetmaster server. On the last two machines you will simply see the outcome of the configurations that you’re going do set on puppetmaster.
Important: all the machines have to be able to communicate between each others. Please make sure DNS is working or set local names/IPs in /etc/hosts file, and do some ping tests before proceeding.
Client setup
On each puppetagent machine, just install the package puppet
apt-get install puppet
By default, the client will look for a host called “puppet” on the network.
If your DNS/hosts file doesn’t have this entry, and it can’t be resolved, you can manually set the name of the puppetmaster in /etc/puppet/puppet.conf file, adding this line under [main] section:
server=puppetmaster.yournet.loc
Now, no more configuration is required from the client side. Just edit /etc/default/puppet to start at boot time and start the service.
# Defaults for puppet - sourced by /etc/init.d/puppet
# Start puppet on boot?
START=yes
# Startup options
DAEMON_OPTS=""
service puppet start
Starting the service, will make automatically a request to the server to be added under his control.
If you want to do some tests, you can eventually use the following command to run puppet only once. This will also force the polling updates, which by default runs every 30 minutes.
puppet agent --no-daemonize --onetime --verbose
You can repeat all these steps on the second client machine.
Server setup
apt-get install puppetmaster
Check if the service is running, otherwise, start it up.
Sign clients’ certificates on the server side
Puppet uses this client/server certificate sign system to add/remove hosts from being managed by the server.
To see who has requested to be “controlled” use this command:
puppet cert --list
This will show all the hosts waiting to be added under puppetmaster server.
puppet cert --sign
This command will add the host.
Puppetmaster configuration files
The main configuration file is /etc/puppet/manifests/site.pp
Inside manifests folder, I’ve created a subfolder called classes with extra definitions (content of these files is showed later in this post).
import 'classes/*.pp'
# This add all the custom .pp files into classes folder
class puppettools {
# Creates a file, setting permissions and content
file { '/usr/local/sbin/puppet_once.sh':
owner => root, group => root, mode => 755,
content => "#!/bin/sh\npuppet agent --no-daemonize --onetime --verbose $1\n",
}
# Install (if not present) some puppet modules required for 'vimconf' class
exec { "install_puppet_module":
command => "puppet module install puppetlabs-stdlib",
path => [ "/bin", "/sbin", "/usr/bin", "/usr/sbin",
"/usr/local/bin", "/usr/local/sbin" ],
onlyif => "test `puppet module list | grep puppetlabs-stdlib | wc -l` -eq 0"
}
}
class vimconf {
# Modify vimrc conf file, enabling syntax on
file_line { 'vim_syntax_on':
path => '/etc/vim/vimrc',
match => '^.*syntax on.*$',
line => 'syntax on',
}
}
node default {
# this will be applied to all nodes without specific node definitions
include packages
include vimconf
include ntp
include puppettools
}
node 'puppetagent01' inherits default {
# this specific node, gets all the default classes PLUS some extras
include mysite
}
Here the content of the single files .pp in classes folder:
It’s important to remember to NOT duplicate entries.
For example, in this case, we have a specific file where we have setup ntp service, including the required package. This means that we do NOT have to add this package in the list into packages.pp, otherwise you will get an error and configs won’t get pushed.
As I’m sure you’ve noted, there are references to some “files”.
Yes, we need some extra configuration, to tell puppet to run as file server as well and where files are located.
In our example we are storing our files in here:
mkdir -p /etc/puppet/files
Now we need to add the following in /etc/puppet/fileserver.conf
[files]
path /etc/puppet/files
allow *
Last bit, is creating the subfolders and place the files required for our configuration:
mkdir -p /etc/puppet/files
cd /etc/puppet/files
mkdir mysite mkdir etc
Inside mysite create mysite_apache.conf and index.html files.
For index.html, you can simply have some text, just for testing purposes.
In this example, we have also setup ntp to be installed and to have a custom ntp.conf file pushed.
For this reason, we need to make sure to have this file present into /etc/puppet/files/etc as declared into our .pp file.
After doing all these changes, you should restart your puppetmaster service on the server.
If all went well, you should have the following:
puppetagent02 host with screen, dselect, vim (installed and with syntax on), ntp (installed, running with custom ntp.conf file)
puppetagent01: with the same as puppetagent02 PLUS apache with a running website
Of course this is just a raw example and you can use template and other super features.
But I think it’s a good start 😉
I’ve used this procedure to create a ESXi host on D945GCLF2 Intel Atom mainboard, with RAID1 storage built in, attached to itself 😉
On that, I have at the moment 3 VMs running (minimal Debian with NFS, FreePBX machine, Debian server with a little LAMP server, SAMBA and web based torrent client)…and more resources available.
How? 🙂
“Simply”, I needed:
HARDWARE
D945GCLF2 Intel Atom mainboard
2GB or RAM DDR2 (667 or 533) in a single module
IDEtoSD adapter
4GB SD card
2 SATA Hard Drives – same capacity (I’ve used 2×2.5″ 160GB – It’s all installed in a little case)
spare SATA CD-ROM and a empty CD-ROM to burn the ESXi ISO (I had issues using a USB stick and utilities like unetbootin or similar… so I ended up with the old fashion but working systems)
SOFTWARE
ESXi 4.1 ISO – I couldn’t find a way to patch most recent ISOs. Patch is required to add support for the integrated NIC. Also 4.1 has all the required functions for this project.
vSphere client installed on your machine, to be able to connect to the host and copy the Debian ISO and manage the HOST.
Procedure
Patch the ISO and burn it on your blank CD.
Connect the IDEtoSD card to the single IDE channel, with the SD. This will be our “main IDE hard drive”.
Make sure to have enabled Hyper Threading Technology in the BIOS.
Connect (temporary) the SATA CD-ROM to one of the two SATA channels, with the ESXi CD in, and complete the installation on the “4GB IDE hard drive” present on the system.
Turn off the host, remove the SATA CD-ROM and connect the two hard drives to the SATA connectors.
Boot up, and create a local datastore with the remaining space of the SD (if this hasn’t been created already automatically) and call it “SD_local“. Here we will store our NFS machine which will provide NFS storage to the host.
Create the RDM devices for our minimal Debian NFS machine follow the below instructions (ensure to make a minimal/basic installation, plus ssh, initramfs-tools, mdadm, nfs-kernel-server, nfs-common, portmap. No graphic interface, no extra packages!).
Create the Debian NFS vm, share the storage using NFS, attach it to the host, and you are ready to go! 😉 The host will be ready to have VMs up and running, with their virtual hard drives stored on a redundant storage.
The scope of this is to allow the Debian NFS VM, which will be stored on the local storage called “SD_local“, to directly access the physical SATA hard drives, create a software RAID1 with them, and using NFS protocol, share the space to the ESXi host and use it to store VMs/ISOs etc.
Of course, this Debian NFS VM, and in particular the SD card, are the single point of failure of this project. But theoretically, a dd of the SD once all is configured can be a good “backup” in case of problems (and a spare 4GB SD home as well 🙂 )
ESXi – How to create a Physical RDM and attach it to a VM